Out-of-Band-Monitoring
vs. agentenbasiertes Monitoring
Moderne Rechenzentren sind auf Monitoring angewiesen, um die Verfügbarkeit aufrechtzuerhalten. Aber nicht alle Monitoring-Ansätze sind gleichwertig. Die meisten traditionellen Tools hängen von Agenten ab, die innerhalb des Betriebssystems laufen — und schaffen blinde Flecken genau dann, wenn Sichtbarkeit am wichtigsten ist.
Out-of-Band-Monitoring verfolgt einen anderen Ansatz. Es verbindet sich direkt mit Hardware-Management-Schnittstellen wie BMC, IPMI und Redfish und bietet Sichtbarkeit, selbst wenn das Betriebssystem ausgefallen ist.
Out-of-Band-Monitoring erklärt
Agentenbasiert: So funktioniert es
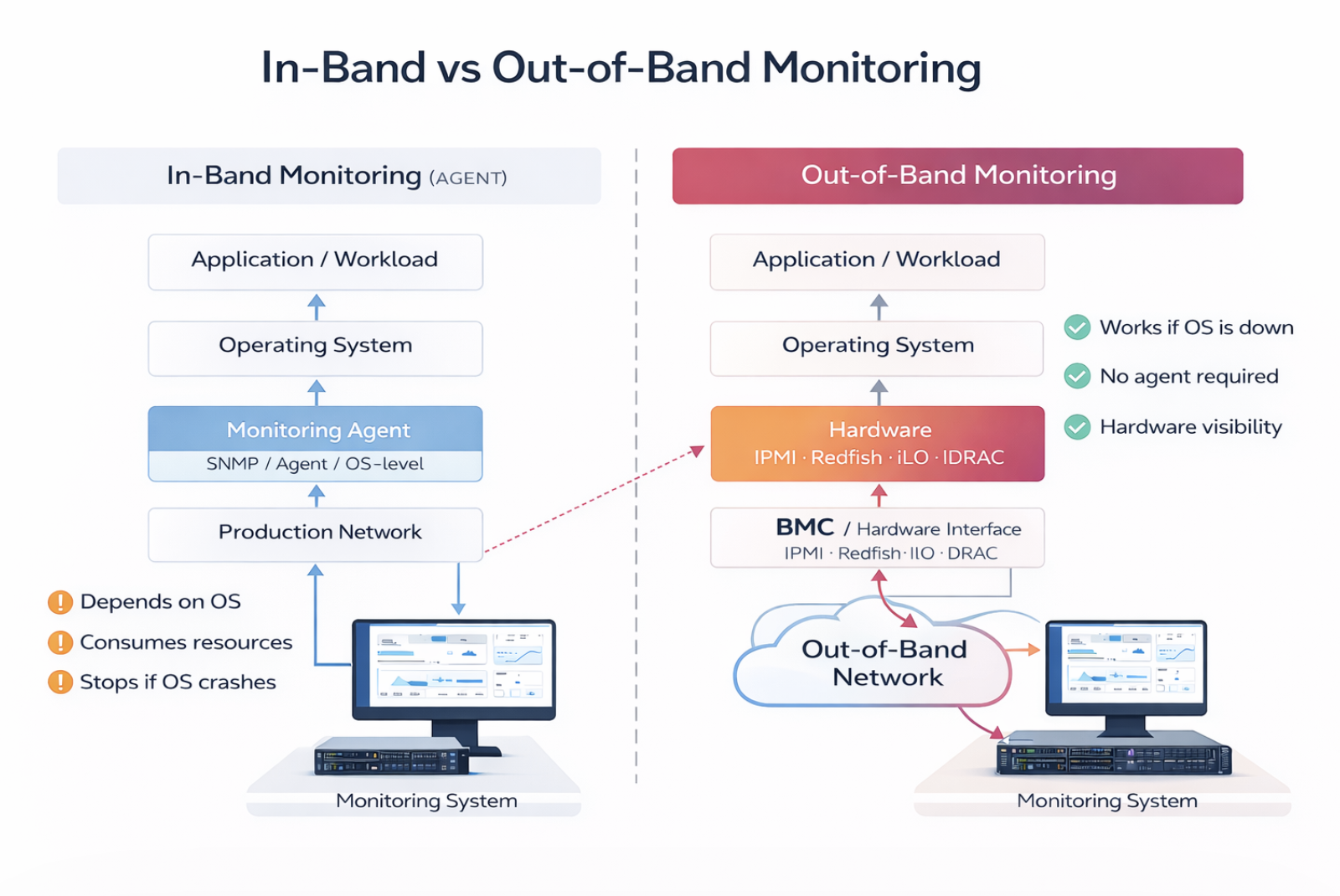
In-Band-Monitoring basiert auf Software-Agenten, die innerhalb des Betriebssystems installiert sind. Diese Agenten sammeln Metriken wie CPU-Auslastung, Speicher- und Festplattenleistung und senden sie an ein zentrales Monitoring-System.
Grenzen agentenbasierten Monitorings
- Abhängig von OS-Verfügbarkeit
- Verbraucht Systemressourcen (CPU, Speicher)
- Kann Hardware-Probleme nicht früh erkennen
- Funktioniert nicht mehr bei OS-Absturz
- Begrenzte Sichtbarkeit physischer Komponenten
Wenn ein Server ausfällt, fällt das agentenbasierte Monitoring oft mit ihm aus.
Ein anderer Ansatz
Out-of-Band-Monitoring verbindet sich direkt mit dem Hardware-Management-Controller des Servers. Dadurch können Monitoring-Systeme unabhängig vom Betriebssystem auf Hardware-Daten zugreifen.
Wesentliche Unterschiede
| Kategorie | Agentenbasiert | Out-of-Band |
|---|---|---|
| Sichtbarkeit | Nur OS-Level-Metriken | Vollständige Hardware-Sichtbarkeit (CPU, Speicher, Disk, Lüfter, Netzteil, Temperatur) |
| Zuverlässigkeit | Stoppt bei OS-Ausfall | Funktioniert auch wenn das System ausgeschaltet oder abgestürzt ist |
| Ressourcennutzung | Verbraucht Systemressourcen | Keine Auswirkungen auf Produktions-Workloads |
| Steuerung | Nur Beobachtung | Remote-Power, BIOS-Zugriff, virtuelle KVM, Fehlerbehebung |
Warum das in modernen Rechenzentren wichtig ist
Mit wachsender Infrastruktur steigen die Kosten von Ausfallzeiten. In Umgebungen wie GPU-Rechenzentren, Colocation-Einrichtungen, Finanzsystemen und Telekommunikationsinfrastrukturen — kann ein unentdecktes Hardware-Problem zu Service-Unterbrechungen, SLA-Strafen und betrieblicher Ineffizienz führen.
Moderne Rechenzentren bewegen sich in Richtung agentenloses Monitoring, Hardware-Sichtbarkeit, einheitliche Steuerung über Hersteller hinweg und reduzierte Abhängigkeit von OS-basierten Tools. Das ist nicht nur ein Upgrade — es ist ein Wandel in der Art, wie Infrastruktur verwaltet wird.
Eine moderne BMC-Alternative
Sensaka DCOS verbindet sich direkt mit Hardware-Management-Schnittstellen in Multi-Vendor-Umgebungen. Statt sich auf fragmentierte Hersteller-Tools zu verlassen, liefert DCOS eine einzige Plattform für Hardware-Observability und Steuerung.
- Echtzeit-Hardware-Monitoring auf Komponentenebene
- Einheitlicher Zugriff auf BMC-Schnittstellen
- Remote-Steuerungsfunktionen (KVM, Power, BIOS)
- Keine Abhängigkeit von Betriebssystemen
- Keine Agent-Installation erforderlich